Function secret sharing (FSS) primitives including:
- 2-party distributed point function (DPF), based on Boyle et al. (CCS '16) or Half-Tree (EUROCRYPT '23).
- 2-party distributed comparison function (DCF), based on Boyle et al. (EUROCRYPT '21) or Grotto (CCS '23).
- 2-party verifiable distributed point function (VDPF), based on Castro & Polychroniadou (EUROCRYPT '22).
- 2-party verifiable distributed multi-point function (VDMPF), based on Castro & Polychroniadou (EUROCRYPT '22).
Features:
- First-class support for GPU (based on CUDA)
- Top-tier performance shown by benchmarks
- Well-commented and documented
- Header-only library, easy for integration
Introduction
Multi-party computation (MPC) is a subfield of cryptography that aims to enable a group of parties (e.g., servers) to jointly compute a function over their inputs while keeping the inputs private.
Secret sharing is a method that distributes a secret among a group of parties, such that no individual party holds any information about the secret. For example, a number \(x\) can be secret-shared into \(x_0, x_1\) via \(x = x_0 + x_1\).
FSS is a scheme to secret-share a function into a group of function shares. Each function share, called as a key, can be individually evaluated on a party. The outputs of the keys are the shares of the original function output. FSS consists of 2 methods: Gen for generating function shares as keys and Eval for evaluating a key to get an output share. FSS's workflow is shown below:
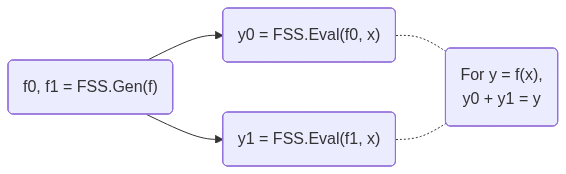
DPF/DCF are FSS for point/comparison functions. They are called out because 2-party DPF/DCF can have \(O(\log N)\) key size, where \(N\) is the input domain size. Meanwhile, 3-or-more-party DPF/DCF and general FSS have \(O(\sqrt{N})\) key size. More details, including the definitions and the implementation details that users must care about, can be found in the documentation of dpf.cuh and dcf.cuh files.
Get Started
Prerequisites
- CMake >= 3.22
- CUDA toolkit >= 12.0 (for C++20 support). Tested on the latest CUDA toolkit.
- OpenSSL 3 (only required for CPU with AES-128 MMO PRG)
Build
Clone the repository:
Option A: Install via CMake and use find_package
Then in your project's CMakeLists.txt:
When configuring your project, point CMake to the install prefix:
Option B: Use as a subdirectory (header-only)
Without installing, you can define the target directly in your CMakeLists.txt, like the samples do:
Then link it in your project:
CPU
This walks through using DPF and DCF on the CPU with AES-128 MMO PRG. This PRG requires OpenSSL.
Include the headers and set up type aliases:
#include <fss/dpf.cuh>#include <fss/dcf.cuh>#include <fss/group/bytes.cuh>#include <fss/prg/aes128_mmo.cuh>constexpr int kInBits = 8; // Input domain: 2^8 = 256 valuesusing In = uint8_t;using Group = fss::group::Bytes;// DPF uses mul=2, DCF uses mul=4using DpfPrg = fss::prg::Aes128Mmo<2>;using DcfPrg = fss::prg::Aes128Mmo<4>;using Dpf = fss::Dpf<kInBits, Group, DpfPrg, In>;using Dcf = fss::Dcf<kInBits, Group, DcfPrg, In>;AES-128 with Matyas-Meyer-Oseas and pre-initialized cipher contexts as a PRG.Definition aes128_mmo.cuh:282-party distributed comparison function (DCF).2-party distributed point function (DPF).Create the PRG with AES keys and instantiate DPF/DCF:
// DPF PRG needs 2 AES keysunsigned char key0[16] = {1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16};unsigned char key1[16] = {16, 15, 14, 13, 12, 11, 10, 9, 8, 7, 6, 5, 4, 3, 2, 1};const unsigned char *keys[2] = {key0, key1};auto ctxs = DpfPrg::CreateCtxs(keys);DpfPrg prg(ctxs);Dpf dpf{prg};Run
Gento generate correction words (keys) from secret inputs:In alpha = 42; // Secret point / thresholdint4 beta = {7, 0, 0, 0}; // Secret payload (LSB of .w must be 0)// Random seeds for the two parties (LSB of .w must be 0)int4 seeds[2] = {{0x11111111, 0x22222222, 0x33333333, 0x44444440},{0x55555555, 0x66666666, 0x77777777, static_cast<int>(0x88888880u)},};Dpf::Cw cws[kInBits + 1];dpf.Gen(cws, seeds, alpha, beta);Run
Evalon each party and reconstruct using the group:// Each party evaluates independentlyint4 y0 = dpf.Eval(false, seeds[0], cws, alpha);int4 y1 = dpf.Eval(true, seeds[1], cws, alpha);// Reconstruct via the group: convert to group elements, add, convert back// For Bytes group this is XOR; for Uint group this is arithmetic additionint4 sum = (Group::From(y0) + Group::From(y1)).Into();// sum == beta at x == alpha, 0 otherwiseFree the AES contexts when done:
DpfPrg::FreeCtxs(ctxs);
DCF follows the same pattern — use DcfPrg (mul=4, needs 4 AES keys), Dcf, and Dcf::Cw. The reconstructed output equals beta when x < alpha and 0 otherwise.
Link with OpenSSL in your CMakeLists.txt:
See samples/dpf_dcf_cpu.cu for the complete working example.
GPU
This walks through using DPF and DCF on the GPU with ChaCha PRG.
Include the headers and set up type aliases:
#include <fss/dpf.cuh>#include <fss/dcf.cuh>#include <fss/group/bytes.cuh>#include <fss/prg/chacha.cuh>constexpr int kInBits = 8;using In = uint8_t;using Group = fss::group::Bytes;// DPF uses mul=2, DCF uses mul=4using DpfPrg = fss::prg::ChaCha<2>;using DcfPrg = fss::prg::ChaCha<4>;using Dpf = fss::Dpf<kInBits, Group, DpfPrg, In>;using Dcf = fss::Dcf<kInBits, Group, DcfPrg, In>;Set up a nonce in constant memory and create the PRG in a kernel:
__constant__ int kNonce[2] = {0x12345678, 0x9abcdef0};__global__ void GenKernel(Dpf::Cw *cws, const int4 *seeds, const In *alphas, const int4 *betas) {int tid = blockIdx.x * blockDim.x + threadIdx.x;DpfPrg prg(kNonce);Dpf dpf{prg};int4 s[2] = {seeds[tid * 2], seeds[tid * 2 + 1]};dpf.Gen(cws + tid * (kInBits + 1), s, alphas[tid], betas[tid]);}Prepare host data, copy to device, and launch the
Genkernel:int4 *d_seeds = /* cudaMalloc + cudaMemcpy seeds to device */;In *d_alphas = /* cudaMalloc + cudaMemcpy alphas to device */;int4 *d_betas = /* cudaMalloc + cudaMemcpy betas to device */;Dpf::Cw *d_cws;cudaMalloc(&d_cws, sizeof(Dpf::Cw) * (kInBits + 1) * N);GenKernel<<<blocks, threads>>>(d_cws, d_seeds, d_alphas, d_betas);Write and launch an
Evalkernel for each party, then copy results back:__global__ void EvalKernel(int4 *ys, bool party, const int4 *seeds, const Dpf::Cw *cws, const In *xs) {int tid = blockIdx.x * blockDim.x + threadIdx.x;DpfPrg prg(kNonce);Dpf dpf{prg};ys[tid] = dpf.Eval(party, seeds[tid], cws + tid * (kInBits + 1), xs[tid]);}// Launch for party 0 and party 1, then copy d_ys back to hostEvalKernel<<<blocks, threads>>>(d_ys, false, d_seeds0, d_cws, d_xs);EvalKernel<<<blocks, threads>>>(d_ys, true, d_seeds1, d_cws, d_xs);Reconstruct on the host using the group, same as the CPU case:
int4 sum = (Group::From(h_y0s[i]) + Group::From(h_y1s[i])).Into();
DCF follows the same pattern — use DcfPrg (mul=4), Dcf, and Dcf::Cw.
See samples/dpf_dcf_gpu.cu for the complete working example.
Compiler Warnings
You may see warnings like "integer constant is so large that it is unsigned" during compilation. These cannot be easily suppressed but are harmless and can be safely ignored.
nvcc 12.8: <tt>Uint</tt> as a <tt>__global__</tt> kernel template argument
nvcc 12.8 fails to compile the stub file when fss::group::Uint<__uint128_t, ...> is used as a template argument to a __global__ kernel — it emits a 128-bit integer literal that g++ cannot parse. __device__ functions are not affected (no stub is generated for them).
Workaround: wrap the type in a plain aggregate struct that satisfies Groupable but has no __uint128_t non-type template parameter in its name. The struct must have no user-declared constructors to remain an aggregate. See third_party/fss/bench.cu for an example.
Benchmarks
Microbenchmarks for DPF/DCF Gen/Eval using Google Benchmark, covering both CPU (AES-128 MMO PRG) and GPU (ChaCha PRG) paths.
Configure with BUILD_BENCH=ON and build the targets:
Run all benchmarks:
Run a subset using --benchmark_filter (regex):
CPU Results
Run on Intel Xeon Platinum 8352V @ 2.10GHz (Ice Lake), single core, performance governor, pinned with taskset -c 0.
GPU Results
Run on NVIDIA RTX A6000 (48GB VRAM), CUDA 12.6, driver 560.35.05. Each iteration runs 1M (2^20) Gen/Eval in parallel. The GPU was warmed up before running the benchmarks.
GPU kernel register usage (compiled for sm_52, --ptxas-options=-v):
| Kernel | Group | Registers | Stack | Smem |
|---|---|---|---|---|
| DpfEval | Uint/Bytes | 39 | ||
| DpfGen | Uint/Bytes | 48 | ||
| DpfEvalAes | Uint | 72 | 992B | 1280B |
| DpfGenAes | Uint | 72 | 992B | 1280B |
| HalfTreeDpfEval | Uint | 41 | ||
| HalfTreeDpfGen | Uint | 47 | ||
| VdpfEval | Uint | 38 | ||
| VdpfGen | Uint | 72 | ||
| DcfEval | Uint | 38 | ||
| DcfGen | Uint | 56 |
The AES-based kernels use shared memory and spill to stack. All other kernels have zero spills.
Flamegraph
Generate a CPU flamegraph with perf and FlameGraph:
Open build/flamegraph.svg in a browser. The graph is interactive: click a frame to zoom in.
License
Apache License, Version 2.0
Copyright (C) 2026 Yulong Ming i@myl.nosp@m.7.or.nosp@m.g